RAG
RAG Pattern
While simple is nice and can give you a good head start, the biggest benefit of using Jarvis on top of Bedrock is Jarvis' ability to use embeddings and the RAG pattern.
So far what we used it to ask a simple question, but we can further its capabilities by providing a text document in the prompt.
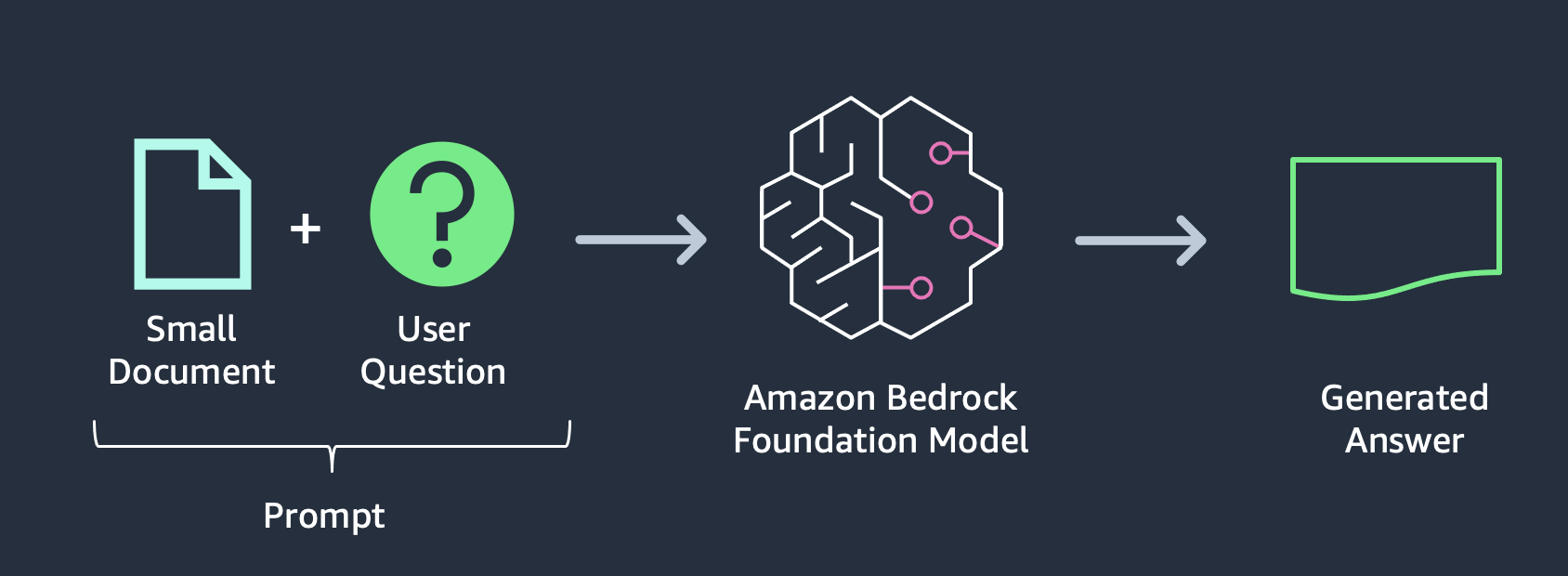
As you can see this is very limited functionality because you will have to find the relevant document by your self and the document size is also limited to the max tokens the FM supports.
RAG - Retrieval-Augmented Generation
"RAG" in the context of AI often refers to the "Retrieval-Augmented Generation" model. This is a hybrid model that combines retrieval and generation techniques to improve the performance of natural language processing tasks.
The traditional approach to language models involves training them to generate text from scratch based on the input they receive. However, sometimes it's more effective to combine generation with retrieval of existing information. This is where RAG models come in.
RAG models consist of two main components:
Retrieval Component: This part of the model retrieves relevant information or passages from a large dataset of text. It's like having a search engine that retrieves relevant snippets of text based on a query.
Generation Component: Once the relevant information is retrieved, the generation component takes over. It generates the final output, incorporating the retrieved information to create coherent and contextually relevant responses.
RAG models are particularly useful for tasks that require a combination of knowledge retrieval and creative generation, such as question answering, content summarization, and more. They leverage the strengths of both techniques to produce high-quality outputs.
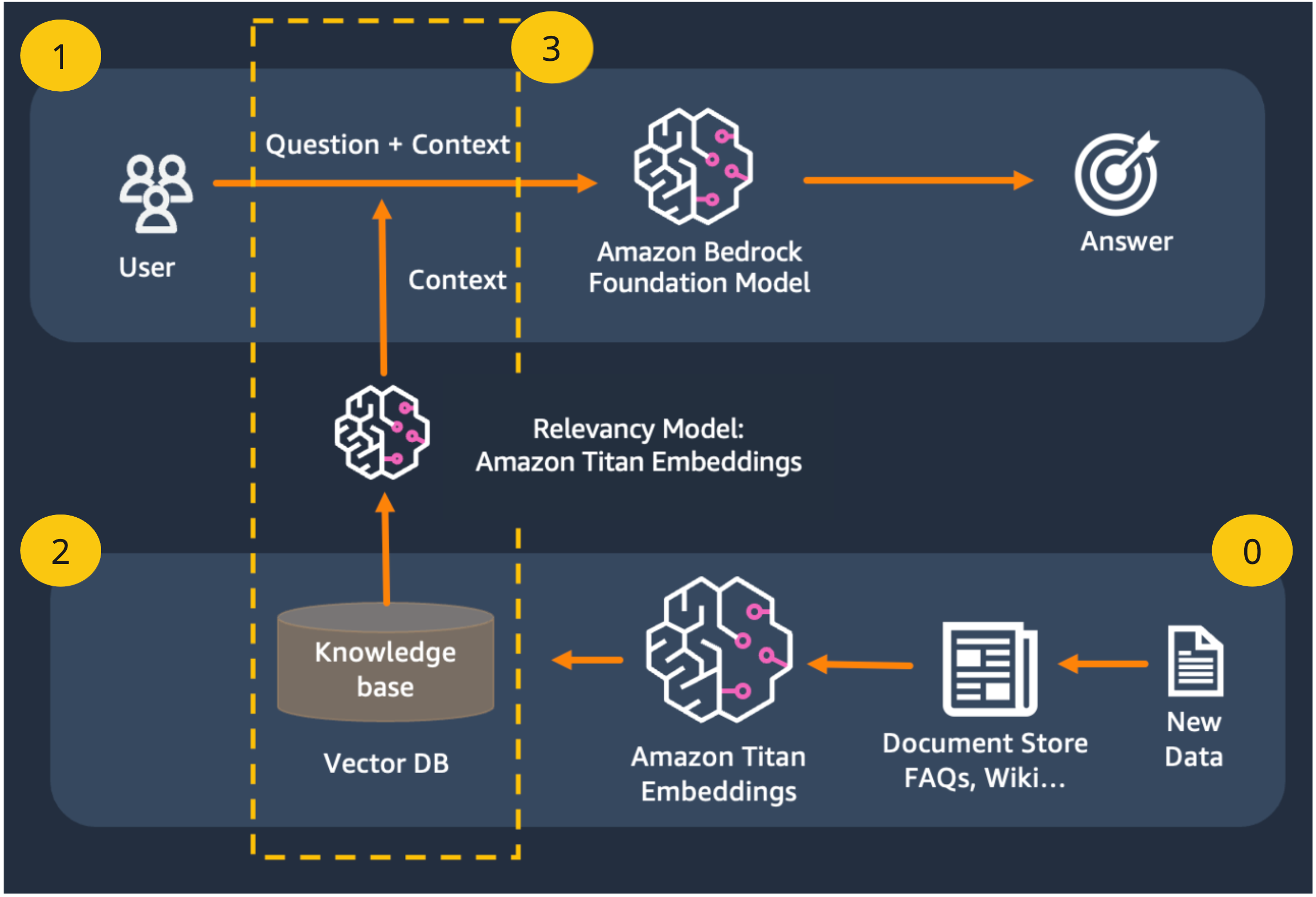
Let's go over what we see here and start with phase 2
Uploading files (2)
Jarvis supports uploading files and taking care of everything that happens.
Jarvis provides the abilities to upload files from SFTP, confluence and webpages.
When you upload files through Jarvis API, Jarvis will do the following:
1. Get the file (SFTP/Confluence/Webpages)
2. Split the docs into chunks
3. Invoke Amazon titan embeddings model to create a vector from the doc chunk
4. Store the vector created by the Amazon titan embeddings model inside Postgres with pgvector support
SPANISH SUPPORTED: Amazon titan embeddings model support working on the spanish language as well, which means you can upload docs in spanish and ask question about them in spanish
Prompt with RAG (1+3)
When jarvis is being asked a question using the prompt API, Jarvis will create a vector from the question and will find for us the most similar vectors in the Postgres DB. only then Jarvis will invoke bedrock model together with the docs it found as the context.
For more information about RAG and vectors jump to GPO confluence